Apache Helix internals
Follow @kishore_b_g
This is a follow up on the Cloudera blog post http://blog.cloudera.com/blog/2013/09/distributed-systems-get-simpler-with-apache-helix/ that covered the core concepts in Helix. I will get into some of the internals of Helix and how it responds to various cluster events.
Roles

Helix roles
Helix divides distributed system components into 3 logical roles as shown in the above figure. It’s important to note that these are just logical components and can be physically co-located within the same process. Each of these logical components have an embedded agent that interacts with other components via Zookeeper.
Controller: The controller is the core component in Helix and is the brain of the system. It hosts the state machine engine, runs the execution algorithm, and issues transitions against the distributed system.
Participant: Each node in the system that performs the core functionality is referred to as a Participant. The Participants run Helix library that invokes callbacks whenever the controller initiates a state transition on the participant. The distributed system is responsible for implementing those callbacks. In this way, Helix remains agnostic of the semantics of a state transition, or how to actually implement the transition. For example, in a LeaderStandby model, the Participant implements methods OnBecomeLeaderFromStandby and OnBecomeStandbyFromLeader. In the above figure p1, p2 represent the partitions of a Resource (Database, Index, Task). Different colors represent the state (e.g master/slave) of the partition.
Spectator: This component represents the external entities that need to observe the state of the system. A spectator is notified of the state changes in the system, so that they can interact with the appropriate participant. For example, a routing/proxy component (a Spectator) can be notified when the routing table has changed, such as when a cluster is expanded or a node fails.
Interaction between components
What are the core requirements of a cluster management system?
- Cluster state/metadata store: Need a durable/persistent and fault tolerant store
- Notification when cluster state changes: the controller needs to detect when nodes start/fail and compute appropriate transitions required to bring the cluster to a healthy state.
- Communication channel between the components: when the controller chooses state transitions to execute, it must reliably communicate these transitions to participants. Once complete, the participants must communicate their status back to the controller.
Helix relies on Zookeeper to meet all of these requirements. By storing all the metadata/cluster state in Zookeeper, the controller itself is stateless and easy to replace on failure. Zookeeper also provides the notification mechanism when nodes start/stop. We also leverage Zookeeper to construct a reliable communication channel between controller and participants. The channel is modeled as a queue in Zookeeper and the controller and participants act as producers and consumers on this queue.
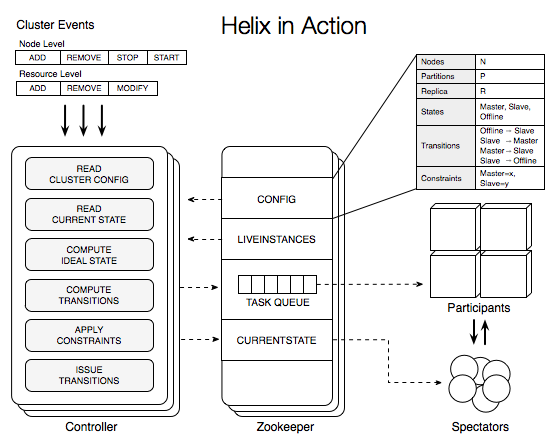
Helix in Action
Thus far we have described how distributed system’s declare their behavior within Helix. Helix execution is a matter of continually monitoring Participant’s state and, as necessary, ordering transitions on the Participants. There are a variety of changes that can occur within a system, both planned and unplanned: starting/stopping of Participants, adding or losing nodes, adding or deleting resources, adding or deleting partitions, among others.
The most crucial feature of the Helix execution algorithm is that it is identical across all of these changes and across all distributed systems! Else, we face a great deal of complexity trying to manage so many combinations of changes and systems, and lose much of Helix’s generality. Let us now step through the Helix execution algorithm.
On every change in the cluster, controller executes a fixed set of actions referred to as rebalance pipeline. This pipeline consists of the following stages that are executed sequentially
- Read cluster configuration: Gathers all metadata about the system such as number of nodes and resources. For each resource, reads the number of partitions, replicas and the FSM (states and transitions) along with the system constraints such as Master:1, Slave:2.
- Read current state: In this stage, the controller reads the current state of the system. Current state reflects the state of each Participants as a result of acting on the transitions issued by the controller.
- Compute Idealstate: After collecting the required information: current state and system configuration, the core rebalancer component of Helix computes the new idealstate satisfies the constraint. One can think of this as the constraint solver. Helix allows application to plugin their own custom rebalancing strategy/algorithm. Helix comes with a default implementation that computes the idealstate that satisfies the constraints and achieves the following objectives.
- Evenly distribute the load among all the nodes.
- When a failure occurs, redistribute the load from failed nodes among remaining nodes while satisfying (1)
- When a new node is added, move resource from existing nodes to new nodes while satisfying (1)
- While satisfying (1), (2), (3) minimize the transitions required to reach idealstate from the currentstate
- Compute transitions: Once the idealstate is computed, Helix looks up the state machine and computes the transitions required to take the system from its current state to idealstate.
- Apply constraints: Blindly issuing all the transitions computed in the previous step might result in violating constraints. Helix computes the subset of the transitions such that executing them in any order will not violate the system constraint.
- Issue transitions: This is the last step in the pipeline where the transitions are sent to the Participants. On receiving the transition, the Helix agent that is embedded in the Participant invokes the appropriate transition handlers provided by the Participant
Once the transition is completed, the success/failure is reflected in the current state. The controller reads the current state and re-runs the rebalancer pipeline until the currentstate converges to idealstate. Once the currentstate is equal to idealstate, the system is considered to be in a stable state. Having this simple goal of computing the idealstate and issuing appropriate transition such that currentstate converge to idealstate makes Helix controller generic.
Up next: Will pick one distributed system (distributed data store, pub/sub, indexing systems) and describe how one can design and build it using Helix.
Have additional questions contact us at IRC #apachehelix or use our mailing list http://helix.incubator.apache.org/mail-lists.html. More info at http://helix.incubator.apache.org
Apache Helix – Year in review 2013
My flight to Peru got overbooked, they offered us another non stop flight 6 hours later. Gladly took the offer. Since I had packed everything, I was jobless. Instead of spending time of facebook and twitter, I thought of writing about all the exciting stuff that happened around Apache Helix in 2013.
Becoming Open Source and Joining Apache Incubator
Helix was open sourced in October 2012 during SOCC. Along with the open source announcement, we entered Apache Incubator. Initially I thought it was a big mistake, primarily due to the Apache release process. It took us 3-4 months to make a release. The only code change I made was changing the package name from com.linkedin to org.apache. Thanks to our mentors (Olivier Lamy and Patrick Hunt) for helping us make the first release that passes all standard Apache checks. I was always cursing “How can the process of making a release be this difficult even after 100’s of projects going through the same path” and I bet every podling goes through the same phase. I really don’t know the reason why first release is difficult and takes a long time but here is a tip: “don’t fight it, just turn off your brain cells and do what ever it takes to make the first release”. Once everything is scripted, next releases are pretty easy. After I made the first release, we have made 3 more releases and each release was done by a different person and things went smoothly each time.
Entering Apache Incubation provides a lot of benefits, which is why many projects choose to do it. ApacheCon provides a very good venue to showcase the project and interact with other Apache project members.
The First Use Case
After we made the first release, it took a while for us to get the first use case outside of LinkedIn. There were few interesting discussions on the mailing list. It was a great learning, on how people think about distributed systems. I found that there is strong hesitancy to think in terms of state machine and transitions. To be honest, it is hard to define systems in terms of FSMs and constraints. It makes one spend a lot of time on the design board than coding while most of us want to get to coding ASAP. We decided to write some recipes to show case the common patterns that we all use: Master-Slave, Leader-Standby, Online-Offline. That allowed users to visualize how their system would look when modeled in terms of FSM and constraints. Following that we had our first production usage: a wall street finance company used the Master Slave pattern and was able to quickly put a distributed system together. We received great feedback:
In fact, the first day of PROD we benefited from Helix since we had to force kill our Master after some emergency change.
The change was made on the Slave, restarted the Slave, then killed the Master to failover to the new Slave.
Everything worked perfectly.
Here is a list of things that Helix is great at
1-It works
2-It’s very flexible
3-The documentation is very good
4-It’s open source, I need to read the code even with good documentation
5-You and your team is very professional and responsive
Things that I like to see
1-I need it to be even more flexible. In particular I need to not fail back to Master. If I restarted a failed Master, I need it to come back up as a Slave instead.
2-I need native DR support.
New Features
Pluggable Rebalancer
The first external use helped us learn a lot what users like to get from the system: an “ability to control the behavior of the framework”. The Helix controller was not flexible enough to plugin custom rebalancers. This motivated us to clean up some code and made the rebalancer pluggable.
Helix Agent
We also realized many need this pattern to support non-JVM based systems. We wrote a standalone Helix agent that can act as a proxy to any process. This was really simple and got us our first big usage outside of LinkedIn at Box. They used standalone Helix agent to manage the node.js processes. Unfortunately, we don’t yet have any documentation on how to use Helix Agent.
https://git-wip-us.apache.org/repos/asf?p=incubator-helix.git;a=tree;f=helix-agent
Python Participant and Spectator
Thanks to Kanak and Jason for writing a Python Helix agent. It allows one to build distributed systems in python. This is also a great way to build sharded, fault-tolerant MySQL and PostgreSQL systems. We are already seeing great interest in Python based Helix Agent.
https://pypi.python.org/pypi/pyhelix
Biggest Weakness
docs, docs, docs.
I can easily say that lot of people have shied away from Helix because of poor documentation, javadocs and apis. We have soo many hidden gems that its reached a point where even our team members within LinkedIn don’t know what Helix can do. Unfortunately, making Helix easy to use was never our priority. The only excuse we have “As all developers we are lazy to write documentation, its not challenging enough”. Also part of the reasoning was that if some one is building a distributed system using Helix, they have to look at the code any ways. In an effort to improve documentation, we did dedicate 0.7.0 release to make our api’s better and would love to get feedback on that.
Skuld
Fortunately or unfortunately I came across Aphyr (Kyle Kingsbury) who thrashes every distributed system out there (don’t get me wrong, he supports it with relevant data points). He tried using Helix for his Skuld project and he had all kinds of problems. I spent a weekend trying to remotely debug the issues and had a really hard time understanding what was going on. Finally, we found that it was because of missing transitions in the state model definition. Helix assumes that one defines the state model correctly and has no validation what so ever built in. After we fixed the state model to include missing transitions every thing worked. However, it gave me a dose of how difficult it is for others to use Helix. Since then we have added more logging and improved our documentation. Special thanks to Aphyr for writing a clj-helix library (a Clojure wrapper around Helix)
Skuid https://github.com/Factual/skuld
clj-helix (https://github.com/Factual/clj-helix) // you can see Helix + Zookeeper in the major drawbacks section :-). I hope its more to do with Zookeeper than Helix.
The Best News (Instagram Using Helix to Build IG Direct)
This came as a real surprise to me. Thanks to Aphyr for suggesting this to Rick Branson in spite of the tough time he had using Helix. The best part was they built the system using Helix without asking us a single question. And I got to know this after they launched the system in production. I never thought that some one would build a system using Helix without asking any questions!!!
Inside LinkedIn
Meanwhile, inside LinkedIn, Helix adoption continues to grow and manages various OLTP, OLAP, streaming and search systems.
Other use cases
Apart from Box and Instagram, Helix is used in other open source systems:
- JBoss workbench: http://docs.jboss.org/jbpm/v6.0/userguide/wb.WorkbenchHighAvailability.html. Thanks to Alexandre Porcelli from RedHat for driving this.
- BooKeeper: Built in metadata store (in progress)
- Apache S4: Enhance cluster management in Apache S4 https://issues.apache.org/jira/browse/S4-110
Graduation to Apache TLP
Hopefully Helix will graduate to a Top Level Project in December’ 2013. If approved, I will be the “Vice President” (without any pay). This will allow us to make releases more often. It should also help get more adoption, for some reason people not familiar with Apache process think that if a project is in Incubation, it means its not ready for production use.
Next Play
2014 will be exciting and interesting. There are lot of frameworks being built on top of low level frameworks, and Helix is designed for just those use cases as it prevents systems builders from “reinventing the wheel” every time. Helix provides high-level APIs so that implementers can think in terms of their cluster instead of primitives in consensus protocols. Here are some areas that we are exploring:
- Getting Helix working to make new systems distributed, like RocksDB
- Managing the entire life cycle of the cluster with the help of systems like Apache YARN and Apache Mesos
- Creating a way for Helix components to efficiently communicate among themselves
- Integrating with systems like Riemann to allow Helix to support automated failure response through monitoring
- Improving on high-level APIs introduced in the 0.7.0 alpha release
Happy Holidays!
